Дисперсия взвешенная рассчитывается по формуле. Абсолютные показатели вариации
Дисперсия в статистике определяется как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. Распространенный способ расчета квадратов отклонений вариантов от средней с их последующим усреднением.
![]()
В экономически-статистическом анализе вариацию признака принято оценивать чаще всего с помощью среднего квадратического отклонения, оно представляет собой корень квадратный из дисперсии.
 (3)
(3)
Характеризует абсолютную колеблемость значений варьирующего признака выражается в тех же единицах измерения, что и варианты. В статистике часто возникает необходимость сравнения вариации различных признаков. Для таких сравнений используется относительный показатель вариации, коэффициент вариации.
Свойства дисперсии:
1)если из всех вариант вычесть какое-либо число, то дисперсия от этого не изменится;
2) если все значения вариант разделить на какое-либо число b, то дисперсия уменьшится в b^2 раз, т.е.
3) если исчислить средний квадрат отклонений от какого-либо числа с неравного средней арифметической, то он будет больше дисперсии . При этом на вполне определенную величину на квадрат разности между средней величиной поc.
![]()
Дисперсию можно определить как разницу между средним квадратом и средней в квадрате.
17. Групповая и межгрупповая вариации. Правило сложения дисперсии
Если статистическая совокупность разбита на группы или части по изучаемому признаку, то для такой совокупности могут быть исчислены следующие виды дисперсии: групповые (частные), средне групповые (частных), и межгрупповая.
Общая
дисперсия
–
отражает вариацию признака за счет всех
условий и причин, действующих в данной
статистической совокупности.
![]()
Групповая дисперсия - равна среднему квадрату отклонений отдельных значений признака внутри группы от средней арифметической этой группы, называемой групповой средней. При этом групповая средняя не совпадает с общей средней для всей совокупности.
![]()
Групповая дисперсия отражает вариацию признака только за счет условий и причин, действующих внутри группы.
Средняя групповых дисперсий - определяется как среднее взвешенное арифметическое из дисперсий групповых, причем весами являются объемы групп.
Межгрупповая дисперсия - равна среднему квадрату отклонений групповых средних от общей средней.
Межгрупповая дисперсия характеризует вариацию результативного признака за счет группировочного признака.
Между рассмотренными видами дисперсий существует определенное соотношение: общая дисперсия равна сумме средней групповой и межгрупповой дисперсии.
Это соотношение называется правилом сложения дисперсии.
18. Динамический ряд и его составные элементы. Виды динамических рядов.
Ряд в статистике - это цифровые данные, показывающие, изменение явления во времени или в пространстве и дающие возможность производить статистическое сравнение явлений как в процессе их развития во времени, так и по различным формам и видам процессов. Благодаря этому можно обнаружить взаимную зависимость явлений.
Процесс развития движения социальных явлений во времени в статистике принято называть динамикой. Для отображения динамики строят ряды динамики (хронологические, временные), которые представляют собой ряды изменяющихся во времени значений статистического показателя (например, число осуждённых за 10 лет), расположенных в хронологическом порядке. Их составными элементами являются цифровые значения данного показателя и периоды или моменты времени, к которым они относятся.
Важнейшая характеристика рядов динамики - их размер (объём, величина) того или иного явления, достигнутых в определённых период или к определённому моменту. Соответственно, величина членов ряда динамики - его уровень. Различают начальный, средний и конечный уровни динамического ряда. Начальный уровень показывает величину первого, конечный - величину последнего члена ряда. Средний уровень представляет собой среднюю хронологическую вариационного рада и исчисляется в зависимости от того, является ли динамический ряд интервальным или моментным.
Ещё одна важная характеристика динамического ряда - время, прошедшее от начального до конечного наблюдения, или число таких наблюдений.
Существуют различные виды рядов динамики, их можно классифицировать по следующим признакам.
1) В зависимости от способа выражения уровней ряды динамики подразделяются на ряды абсолютных и производных показателей (относительных и средних величин).
2) В зависимости от того, как выражают уровни ряда состояние явления на определённые моменты времени (на начало месяца, квартала, года и т.п.) или его величину за определённые интервалы времени (например, за сутки, месяц, год и т.п.), различают соответственно моментные и интервальные ряды динамики. Моментные ряды в аналитической работе правоохранительных органов используются сравнительно редко.
В теории статистики выделяют рады динамики и по ряду других классификационных признаков: в зависимости от расстояния между уровнями - с равностоящими уровнями и неравностоящими уровнями во времени; в зависимости от наличия основной тенденции изучаемого процесса - стационарные и не стационарные. При анализе динамических рядов исходят из следующего уровни ряда представляют в виде составляющих:
Y t = TP + Е (t)
где ТР – детерминированная составляющая определяющая общую тенденцию изменения во времени или тренд.
Е (t) – случайная компонента, вызывающая колеблимость уровней.
Решение.
В качестве меры рассеивания значений случайной величины используется дисперсия
Дисперсия (слово дисперсия означает "рассеяние") есть мера рассеивания значений случайной величины относительно ее математического ожидания. Дисперсией называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания
Если случайная величина - дискретная с бесконечным, но счетным множеством значений, то
если ряд в правой части равенства сходится.
Свойства дисперсии.
- 1. Дисперсия постоянной величины равна нулю
- 2. Дисперсия суммы случайных величин равна сумме дисперсий
- 3. Постоянный множитель можно выносить за знак дисперсии в квадрате
Дисперсия разности случайных величин равна сумме дисперсий
Это свойство является следствием второго и третьего свойств. Дисперсии могут только складываться.
Дисперсию удобно вычислять по формуле, которую легко получить, используя свойства дисперсии
Дисперсия всегда величина положительная .
Дисперсия имеет размерность квадрата размерности самой случайной величины, что не всегда удобно. Поэтому в качестве показателя рассеяния используют также величину
Средним квадратическим отклонением (стандартным отклонением или стандартом) случайной величиныназывается арифметическое значение корня квадратного из её дисперсии
Бросают две монеты достоинством 2 и 5 рублей. Если монета выпадает гербом, то начисляют ноль очков, а если цифрой, то число очков, равное достоинству монеты. Найти математическое ожидание и дисперсию числа очков.
Решение. Найдем вначале распределение случайной величины Х - числа очков. Все комбинации - (2;5),(2;0),(0;5),(0;0) - равновероятны и закон распределения:

Математическое ожидание:
Дисперсию найдем по формуле
для чего вычислим
Пример 2.
Найти неизвестную вероятность р , математическое ожидание и дисперсию дискретной случайной величины, заданной таблицей распределения вероятностей
Находим математическое ожидание и дисперсию:
M (X ) = 00,0081 + 10,0756 + 20,2646 + 3 0,4116 + +40,2401=2,8
Для вычисления дисперсии воспользуемся формулой (19.4)
D (X ) = 020 ,0081 + 120,0756 + 220,2646 + 320,4116 + 420,2401 - 2,82 = 8,68 -

Пример 3. Два равносильных спортсмена проводят турнир, который длится или до первой победы одного из них, или до тех пор, пока не будет сыграно пять партий. Вероятность победы в одной партии для каждого из спортсменов равна 0,3, а вероятность ничейного исхода партии 0,4. Найти закон распределения, математическое ожидание и дисперсию числа сыгранных партий.
Решение. Случайная величина Х - количество сыгранных партий, принимает значения от 1 до 5, т. е.
Определим вероятности окончания матча. Матч закончится на первой партии, если кто-то их спортсменов выиграл. Вероятность выигрыша равна
Р (1) = 0,3+0,3 =0,6.
Если же была ничья (вероятность ничьей равна 1 - 0,6 = 0,4), то матч продолжается. Матч закончится на второй партии, если в первой была ничья, а во второй кто-то выиграл. Вероятность
Р (2) = 0,4 0,6=0,24.
Аналогично, матч закончится на третьей партии, если было подряд две ничьи и опять кто-то выиграл
Р (3) = 0,4 0,4 0,6 = 0,096. Р (4)= 0,4 0,4 0,4 0,6=0,0384.
Пятая партия в любом варианте последняя.
Р (5)= 1 - (Р (1)+Р (2)+Р (3)+Р (4)) = 0,0256.
Сведем все в таблицу. Закон распределения случайной величины "число выигранных партий" имеет вид
Математическое ожидание
Дисперсию вычисляем по формуле (19.4)
Стандартные дискретные распределения.
Биномиальное распределение. Пусть реализуется схема опытов Бернулли: проводится n одинаковых независимых опытов, в каждом из которых событие A может появиться с постоянной вероятностью p и не появится с вероятностью
(см. лекцию 18).
Число появлений события A в этих n опытах есть дискретная случайная величина X , возможные значения которой:
0; 1; 2; ... ; m ; ... ; n.
Вероятность появления m событий A в конкретной серии из n опытов с и закон распределения такой случайной величины задается формулой Бернулли (см. лекцию 18)
 |



Числовые характеристики случайной величины X распределенной по биномиальному закону:

Если n велико (), то, при, формула (19.6) переходит в формулу
а табулированная функция Гаусса (таблица значений функции Гаусса приведена в конце 18 лекции).
На практике часто важна не сама вероятность появления m событий A в конкретной серии из n опытов, а вероятность того, что событие А появится не менее
раз и не более раз, т. е. вероятность того, что Х принимает значения
Для этого надо просуммировать вероятности
Если n велико (), то, при, формула (19.9) переходит в приближенную формулу

табулированная функция. Таблицы приведены в конце лекции 18.
При использовании таблиц надо учесть, что
Пример 1 . Автомобиль, подъезжая к перекрестку, может продолжить движение по любой из трех дорог: A, B или C с одинаковой вероятностью. К перекрестку подъезжают пять автомобилей. Найти среднее число автомашин, которое поедет по дороге A и вероятность того, что по дороге B поедет три автомобиля.
Решение. Число автомашин проезжающих по каждой из дорог является случайной величиной. Если предположить, что все подъезжающие к перекрестку автомобили совершают поездку независимо друг от друга, то эта случайная величина распределена по биномиальному закону с
n = 5 и p = .
Следовательно, среднее число автомашин, которое проследует по дороге A, есть по формуле (19.7)
а искомая вероятность при
Пример 2. Вероятность отказа прибора при каждом испытании 0,1. Производится 60 испытаний прибора. Какова вероятность того, что отказ прибора произойдёт: а) 15 раз; б) не более 15 раз?
а. Так как число испытаний 60, то используем формулу (19.8)
По таблице 1 приложения к лекции 18 находим
б . Используем формулу (19.10).
По таблице 2 приложения к лекции 18
- - 0,495
- 0,49995
Распределение Пуассона) закон редких явлений). Если n велико, а р мало (), при этом произведение пр сохраняет постоянное значение, которое обозначим л,
то формула (19.6) переходит в формулу Пуассона

Закон распределения Пуассона имеет вид:

Очевидно, что определение закона Пуассона корректно, т.к. основное свойство ряда распределения
выполнено, т.к. сумма ряда
В скобках записано разложение в ряд функции при
Теорема. Математическое ожидание и дисперсия случайной величины, распределенной по закону Пуассона, совпадают и равны параметру этого закона, т.е.
Доказательство.
Пример. Для продвижения своей продукции на рынок фирма раскладывает по почтовым ящикам рекламные листки. Прежний опыт работы показывает, что примерно в одном случае из 2 000 следует заказ. Найти вероятность того, что при размещении 10 000 рекламных листков поступит хотя бы один заказ, среднее число поступивших заказов и дисперсию числа поступивших заказов.
Решение . Здесь
Вероятность того, что поступит хотя бы один заказ, найдем через вероятность противоположного события, т.е.
Случайный поток событий. Потоком событий называется последовательность событий, происходящие в случайные моменты времени. Типичными примерами потоков являются сбои в компьютерных сетях, вызовы на телефонных станциях, поток заявок на ремонт оборудования и т. д.
Поток событий называется стационарным , если вероятность попадания того или иного числа событий на временной интервал длины зависит только от длины интервала и не зависит не зависит от расположения временного интервала на оси времени.
Условию стационарности удовлетворяет поток заявок, вероятностные характеристики которого не зависят от времени. В частности, для стационарного потока характерна постоянная плотность (среднее число заявок в единицу времени). На практике часто встречаются потоки заявок, которые (по крайней мере, на ограниченном отрезке времени) могут рассматриваться как стационарные. Например, поток вызовов на городской телефонной станции на участке времени от 12 до 13 часов может считаться стационарным. Тот же поток в течение целых суток уже не может считаться стационарным (ночью плотность вызовов значительно меньше, чем днем).
Поток событий называется потоком с отсутствием последействия , если для любых неперекрывающихся участков времени число событий, попадающих на один из них, не зависит от числа событий, попадающих на другие.
Условие отсутствия последействия - наиболее существенное для простейшего потока - означает, что заявки поступают в систему независимо друг от друга. Например, поток пассажиров, входящие на станцию метро, можно считать потоком без последействия потому, что причины, обусловившие приход отдельного пассажира именно в тот, а не другой момент, как правило, не связаны с аналогичными причинами для других пассажиров. Однако условие отсутствия последействия может быть легко нарушено за счет появления такой зависимости. Например, поток пассажиров, покидающих станцию метро, уже не может считаться потоком без последействия, так как моменты выхода пассажиров, прибывших одним и тем же поездом, зависимы между собой.
Поток событий называется ординарным , если вероятность попадания на малый интервал времени t двух или более событий пренебрежимо мала по сравнению с вероятностью попадания одного события (в этой связи закон Пуассона называют законом редких событий).
Условие ординарности означает, что заявки приходят поодиночке, а не парами, тройками и т. д. дисперсия отклонение распределение бернулли
Например, поток клиентов, входящих в парикмахерскую, может считаться практически ординарным. Если в неординарном потоке заявки поступают только парами, только тройками и т. д., то неординарный поток легко свести к ординарному; для этого достаточно вместо потока отдельных заявок рассмотреть поток пар, троек и т. д. Сложнее будет, если каждая заявка случайным образом может оказаться двойной, тройной и т. д. Тогда уже приходится иметь дело с потоком не однородных, а разнородных событий.
Если поток событий обладает всеми тремя свойствами (т. е. стационарен, ординарен и не имеет последействия), то он называется простейшим (или стационарным пуассоновским) потоком. Название "пуассоновский" связано с тем, что при соблюдении перечисленных условий число событий, попадающих на любой фиксированный интервал времени, будет распределено по закону Пуассона
Здесь - среднее число событий A , появляющихся за единицу времени.
Этот закон однопараметрический, т.е. для его задания требуется знать только один параметр. Можно показать, что математическое ожидание и дисперсия в законе Пуассона численно равны:
Пример . Пусть в середине рабочего дня среднее число запросов равняется 2 в секунду. Какова вероятность того, что 1) за секунду не поступит ни одной заявки, 2) за две секунды поступит 10 заявок?
Решение. Поскольку правомерность применения закона Пуассона не вызывает сомнения и его параметр задан (= 2), то решение задачи сводится к применении формулы Пуассона (19.11)
1) t = 1, m = 0:
2) t = 2, m = 10:
Закон больших чисел. Математическим основанием того факта, что значения случайной величины группируются около некоторых постоянных величин, является закон больших чисел.
Исторически первой формулировкой закона больших чисел стала теорема Бернулли:
"При неограниченном увеличении числа одинаковых и независимых опытов n частота появления события A сходится по вероятности к его вероятности", т.е.
где частота появления события A в n опытах,
Содержательно выражение (19.10) означает, что при большом числе опытов частота появления события A может заменять неизвестную вероятность этого события и чем больше число проведенных опытов, тем ближе р* к р. Интересен исторический факт. К. Пирсон бросал монету 12000 раз и герб у него выпал 6019 раз (частота 0.5016). При бросании этой же монеты 24000 раз он получил 12012 выпадений герба, т.е. частоту 0.5005.
Наиболее важной формой закона больших чисел является теорема Чебышева: при неограниченном возрастании числа независимых, имеющих конечную дисперсию и проводимых в одинаковых условиях опытов среднее арифметическое наблюденных значений случайной величины сходится по вероятности к ее математическому ожиданию . В аналитической форме эта теорема может быть записана так:
Теорема Чебышева кроме фундаментального теоретического значения имеет и важное практическое применение, например, в теории измерений. Проведя n измерений некоторой величины х , получают различные несовпадающие значения х 1, х 2, ..., хn . За приближенное значение измеряемой величины х принимают среднее арифметическое наблюденных значений
При этом, чем больше будет проведено опытов, тем точнее будет полученный результат. Дело в том, что дисперсия величины убывает с возрастанием числа проведенных опытов, т.к.
D (x 1) = D (x 2)=…= D (xn ) D (x ) , то
Соотношение (19.13) показывает, что и при высокой неточности приборов измерения (большая величина) за счет увеличения количества измерений можно получать результат со сколь угодно высокой точностью.
Используя формулу (19.10) можно найти вероятность того, что статистическая частота отклоняется от вероятности не более, чем на


Пример. Вероятность события в каждом испытании равна 0,4. Сколько нужно провести испытаний, чтобы с вероятностью, не меньшей, чем 0,8 ожидать, что относительная частота события будет отклоняться от вероятности по модулю менее, чем на 0,01?
Решение. По формуле (19.14)


следовательно, по таблице два приложения
следовательно, n 3932.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

Виды дисперсий:
Общая дисперсия характеризует вариацию признака всей совокупности под влиянием всех тех факторов, которые обусловили данную вариацию. Эта величина определяется по формуле
где - общая средняя арифметическая всей исследуемой совокупности.
Средняя внутригрупповая дисперсия свидетельствует о случайной вариации, которая может возникнуть под влиянием каких-либо неучтенных факторов и которая не зависит от признака-фактора, положенного в основу группировки. Данная дисперсия рассчитывается следующим образом: сначала рассчитываются дисперсии по отдельным группам (), затем рассчитывается средняя внутригрупповая дисперсия:
 где
n i -
число единиц в группе
где
n i -
число единиц в группе
Межгрупповая дисперсия (дисперсия групповых средних) характеризует систематическую вариацию, т.е. различия в величине исследуемого признака, возникающие под влиянием признака-фактора, который положен в основу группировки.

где - средняя величина по отдельной группе.
Все три вида дисперсии связаны между собой: общая дисперсия равна сумме средней внутригрупповой дисперсии и межгрупповой дисперсии:
![]()
Свойства:
25 Относительные показатели вариации
|
Коэффициент осцилляции |
|
|
Относительное линейное отклонение |
|
|
Коэффициент вариации |
|
Коэф. Осц. о тражает относительную колеблемость крайних значений признака вокруг средней. Отн. лин. откл . характеризует долю усредненного значения признака абсолютных отклонений от средней величины. Коэф. Вариации является наиболее распространенным показателем колеблемости, используемым для оценки типичности средних величин.
В статистике совокупности, имеющие коэффициент вариации больше 30–35 %, принято считать неоднородными.
Закономерность рядов распределения. Моменты распределения. Показатели формы распределения
В вариационных рядах существует связь между частотами и значениями варьирующего признака: с увеличением признака величина частоты сначала возрастает до определённой границы, а потом уменьшается. Такие изменения называются закономерностями распределения.
Форму распределения изучают с помощью показателей асимметрии и эксцесса. При исчислении указанных показателей используют моменты распределения.
Моментом k-го порядка называют среднюю из k-х степеней отклонений вариантов значений признака от некоторой постоянной величины. Порядок момента определяется величиной k. При анализе вариационных рядов ограничиваются расчетом моментов первых четырех порядков. При исчислении моментов в качестве весов могут быть использованы частоты или частости. В зависимости от выбора постоянной величины различают начальные, условные и центральные моменты.
Показатели формы распределения:
Асимметрия (As) показатель характеризующий степень асимметричности распределения.

Следовательно,
при (левосторонней) отрицательной
асимметрии  .
При (правосторонней) положительной
асимметрии
.
При (правосторонней) положительной
асимметрии .
.
Для расчета асимметрии можно использовать центральные моменты. Тогда:
 ,
,
где μ 3 – центральный момент третьего порядка.
- эксцесс (Е к ) характеризует крутизну графика функции в сравнении с с нормальным распределением при той же силе вариации:
 ,
,
где μ 4 – центральный момент 4-ого порядка.
Закон нормального распределения
Для нормального распределения (распределения Гаусса) функция распределения имеет следующий вид:


Матожидание- стандартное отклонение
Нормальное распределение симметрично и для него характерно следующее соотношение: Хср=Ме=Мо
Эксцесс нормального распределения равен 3, а коэффициент асимметрии 0.
Кривая нормального распределения представляет собой полигон(симметричная колокобразная прямая)
Виды дисперсий. Правило сложения дисперсий. Сущность эмпирического коэффициента детерминации.
Если исходная совокупность разделена на группы по какому-то существенному признаку, то вычисляют следующие виды дисперсий:
Общая дисперсия исходной совокупности:
где - общая средняя величина исходной совокупности;f– частоты исходной совокупности. Общая дисперсия характеризует отклонение индивидуальных значений признака от общей средней величины исходной совокупности.
Внутригрупповые дисперсии:
где j- номер группы;- средняя величина в каждойj-ой группе;- частотыj-ой группы. Внутригрупповые дисперсии характеризуют отклонение индивидуального значения признака в каждой группе от групповой средней величины. Из всех внутригрупповых дисперсий вычисляют среднюю по формуле:, где- численность единиц в каждойj-ой группе.
Межгрупповая дисперсия:
Межгрупповая дисперсия характеризует отклонение групповых средних величин от общей средней величины исходной совокупности.
Правило сложения дисперсий заключается в том, что общая дисперсия исходной совокупности должна быть равна сумме межгрупповой и средней из внутригрупповых дисперсий:
Эмпирический коэффициент детерминации показывает долю вариации изучаемого признака, обусловленную вариацией группировочного признака, и рассчитывается по формуле:
Способ отсчета от условного нуля (способ моментов) для расчета средней величины и дисперсии
Расчет дисперсии способом моментов основан на использовании формулы и 3 и 4 свойств дисперсии.
(3.Если все значения признака (варианты) увеличить (уменьшить) на какое-то постоянное число А, то дисперсия новой совокупности не изменится.
4.Если все значения признака (варианты) увеличить (умножить) в К раз, где К – постоянное число, то дисперсия новой совокупности увеличится (уменьшится) в К 2 раз.)
Получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:

А- условный ноль, равный варианте с максимальной частотой (середина интервала с максимальной частотой)
Расчет средней величины способом моментов также основан на использовании свойств средней.
![]()
Понятие о выборочном наблюдении. Этапы исследования экономических явлений выборочным методом
Выборочным называют наблюдение, при котором обследованию и изучению подвергаются не все единицы исходной совокупности, а только часть единиц, при этом результат обследования части совокупности распространяется на всю исходную совокупность. Совокупность, из которой производится отбор единиц для дальнейшего обследования и изучения называется генеральной и все показатели, характеризующие эту совокупность, называютсягенеральными .
Возможные пределы отклонений выборочной средней величины от генеральной средней величины называют ошибкой выборки .
Совокупность отобранных единиц называется выборочной и все показатели, характеризующие эту совокупность, называютсявыборочными .
Выборочное исследование включает следующие этапы:
Характеристика объекта исследования (массовые экономические явления). Если генеральная совокупность небольшая, то выборку проводить не рекомендуется, необходимо сплошное исследование;
Расчет объема выборки. Важно определить оптимальный объем, который позволит при наименьших затратах получить ошибку выборки в пределах допустимой;
Проведение отбора единиц наблюдения с учетом требований случайности, пропорциональности.
Доказательство репрезентативности, основанное на оценке ошибки выборки. Для случайной выборки ошибка рассчитывается с использованием формул. Для целевой выборки репрезентативность оценивается с помощью качественных методов (сравнения, эксперимента);
Анализ выборочной совокупности. Если сформированная выборка отвечает требованиям репрезентативности, то проводится ее анализ с использованием аналитических показателей (средних, относительных и проч.)
Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Число рабочих, |
Середина интервала, |
Расчетные значения |
|||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки:
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
1 Расчет дисперсии способом моментов
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
- если все значения признака уменьшить или увеличить на одну и ту же величину А, то дисперсия от этого не уменьшится:
 ,
,
 , то или
, то или 
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту; 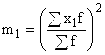 – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


- рассчитываем дисперсию:
2 Расчет дисперсии альтернативного признака
Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
3 Межгрупповая дисперсия. Правило сложения дисперсий
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.